Apache Kafka
This article covers running a Kafka cluster on a development machine using a pre-made Docker image, playing around with the command line tools distributed with Apache Kafka and writing basic producers and consumers.
The source code associated with this article can be found here
How to run Apache Kafka
The simplest way: docker-compose up with the following docker-compose.yml
To run a single instance of Kafka on the localhost, with ports exposed to localhost:
version: '3'
# based on https://github.com/wurstmeister/kafka-docker
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka
ports:
- "9092:9092"
- "1099:1099" # for JMX - not needed unless we want to monitor the service
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_JMX_OPTS: "-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=127.0.0.1 -Dcom.sun.management.jmxremote.rmi.port=1099"
JMX_PORT: 1099
volumes:
- /var/run/docker.sock:/var/run/docker.sock
Another option, if we want to scale the Kafka cluster is to run:
docker-compose up -d
and then
docker-compose scale kafka=2
However, in order for this to run, we need to make some changes to our docker-compose file:
version: '3'
# based on https://github.com/wurstmeister/kafka-docker
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181"
kafka:
image: wurstmeister/kafka
ports:
- "9092" # we do not publish these ports anymore to host
environment:
# we remove the KAFKA_ADVERTISED_HOST_NAME property
HOSTNAME_COMMAND: "route -n | awk '/UG[ \t]/{print $$2}'"
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
# we drop completely the JMX part
volumes:
- /var/run/docker.sock:/var/run/docker.sock
In this docker image, Kafka is installed in /opt/kafka, thus running
docker exec testkafka_kafka_2 ls /opt/kafka/bin
will get get us the list of all Kafka binaries. Let's connect to one of the two Kafka instances.
docker exec -it testkafka_kafka_2 bash
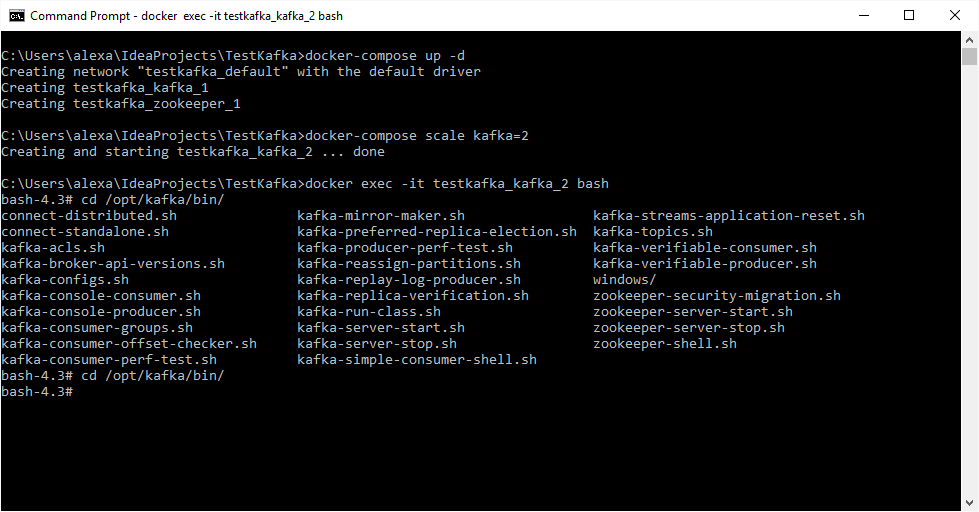
However, if JMX is still specified, the JMX_PORT is already set and in use by the Kafka daemon, so in order to run commands to Kafka we need to make a little hack:
$>JMX_PORT=1100
$>KAFKA_JMX_OPTS=""
Then we can play:
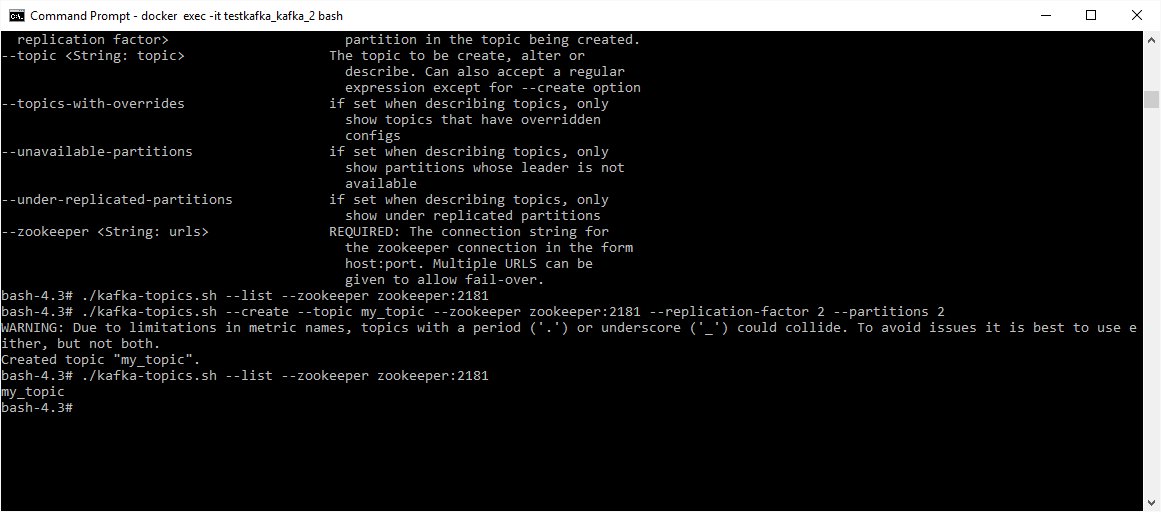
To produce messages to my_topic:
bash-4.3# ./kafka-console-producer.sh --topic my_topic --broker-list testkafka_kafka_1:9092
To read messages from my_topic:
bash-4.3# ./kafka-console-consumer.sh --topic my_topic --zookeeper zookeeper:2181 --from-beginning
Basic Concepts
Apache Kafka is a high-throughput distributed pub-sub messaging system, with on-disk persistence. In essence, it can be viewed as a distributed immutable ordered (by time) sequence of messages. Each consumer has a private read-only cursor, which it can reset at any time. This way of storing messages / events makes Kafka appropriate as a distributed store for event sourcing architectural pattern.
Concepts:
- A Kafka cluster is a grouping of multiple Kafka brokers (could be hundreds).
- Topics can span over a multitude of brokers.
- Each topic has one or more partitions.
- Each partition is maintained over one or more brokers.
- Each partition must fit on one machine.
- Each partition is mutually exclusive from each other. This means the same message wil never appear simultaneously on two partitions.
- If there is no partitioning scheme set up, messages are put to partitions in a round-robin fashion.
- Message order is guaranteed only on a per-partition basis.
Partitioning trade-offs:
- The more partitions the more load on Zookeeper. Since Zookeeper keeps its data in memory only, resources on the Zookeeper machine can become constrainted.
- There is no global order in a topic with several partitions.
- As each partition can only fit on a single machine. This imposes the limit to how much a single partition can grow.
Fault tolerance:
- Broker failure
- Disk failure
- Network failure
Replication factor is set on a topic level, thus can vary from topic to topic but not from partition to partition.
When we connect to both docker instances that we started in our demo cluster, because we set for topic my_topic 2 partitions and replication factor 2, we see the same picture:
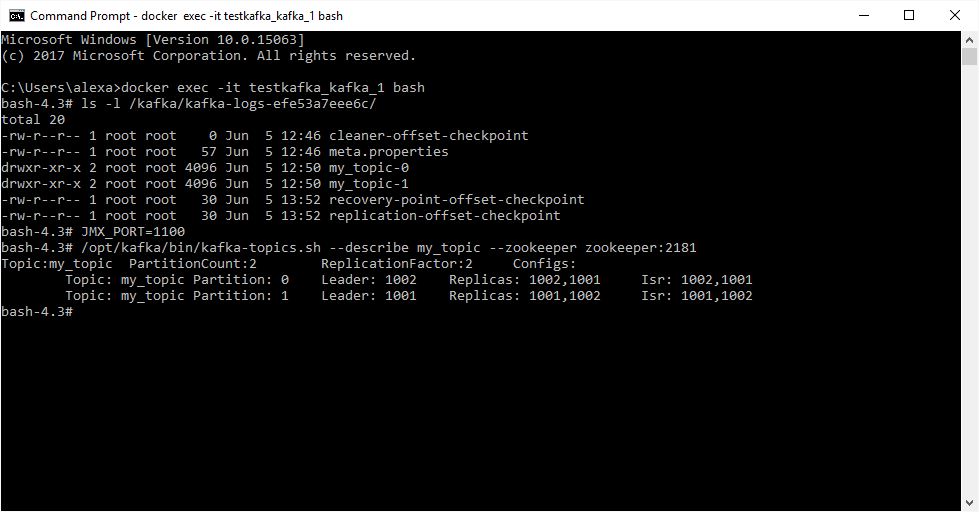
In the image above, ISR means in-sync replicas. If we decide to kill one docker container, we get:
bash-4.3# /opt/kafka/bin/kafka-topics.sh --describe my_topic --zookeeper zookeeper:2181
Topic:my_topic PartitionCount:2 ReplicationFactor:2 Configs:
Topic: my_topic Partition: 0 Leader: 1001 Replicas: 1002,1001 Isr: 1001
Topic: my_topic Partition: 1 Leader: 1001 Replicas: 1001,1002 Isr: 1001
The cluster has readjusted itself. Leader for partition 0 has been assigned 1001 (instead of 1002 which was previously), we still have two replicas, but ISR is only 1001.
If we start the stopped container again, we get:
bash-4.3# /opt/kafka/bin/kafka-topics.sh --describe my_topic --zookeeper zookeeper:2181
Topic:my_topic PartitionCount:2 ReplicationFactor:2 Configs:
Topic: my_topic Partition: 0 Leader: 1001 Replicas: 1002,1001 Isr: 1001,1002
Topic: my_topic Partition: 1 Leader: 1001 Replicas: 1001,1002 Isr: 1001,1002
```
Leader for both partitions stay the same, but this time ISR are both 1001 and 1002.
[How many topics can be created in Apache Kafka?](https://www.quora.com/How-many-topics-can-be-created-in-Apache-Kafka/answer/Jay-Kreps?srid=55SS)
*Retention policy:*
Retention is regardless of whether any consumer has read any message. Default retention time is 7 days. Unlike RabbitMQ for instance, where TTL is set on a per-message basis, in Kafka retention policy is set on a per-topic basis.
### Debugging Kafka Clients
There are two basic ways to debug Kafka clients when you want to run everything on your machine. The simplest way is to run a single kafka instance and map its port to localhost. Thus, in the client application, there will be only one Kafka broker to connect to, that is to `localhost`.
However, there is another one, slightly more complex but more rewarding as one can scale as many brokers as he/she wishes. This requires the creation of another service in the docker compose file which runs the Java application to debug, because it is needed that this app runs in the same docker network as the rest of the cluster. It also requires remote debugging enabled and mapping of the project directory in a volume in the docker container that runs the app. Here is the updated `docker-compose.yml` as it is configured on my machine.
```yml
version: '3'
# based on https://github.com/wurstmeister/kafka-docker
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181"
kafka_client_app: # the container to which my java client connects to
image: openjdk
ports:
- "8000:8000" # expose the debugger port to localhost
depends_on:
- kafka
command: java -agentlib:jdwp=transport=dt_socket,server=y,address=8000,suspend=y -Dbootstrap.servers=kafka:9092 -cp /myapp/out/production/TestKafka:/myapp/lib/* ro.alexandrugris.BasicKafkaProducer # wait for debugger in suspend mode
volumes:
- C:\Users\alexa\IdeaProjects\TestKafka:/myapp # map the project to the container
kafka: # for scale
image: wurstmeister/kafka
depends_on:
- zookeeper
ports:
- "9092"
environment:
HOSTNAME_COMMAND: "route -n | awk '/UG[ \t]/{print $$2}'"
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
# create a topic on start
KAFKA_CREATE_TOPICS: "alexandrugris.my_topic:5:2:compact" # 5 partitions, 2 replicas
volumes:
- /var/run/docker.sock:/var/run/docker.sock
And some screenshots:
Debugger Configuration in Idea
Breakpoint in remote debugging config
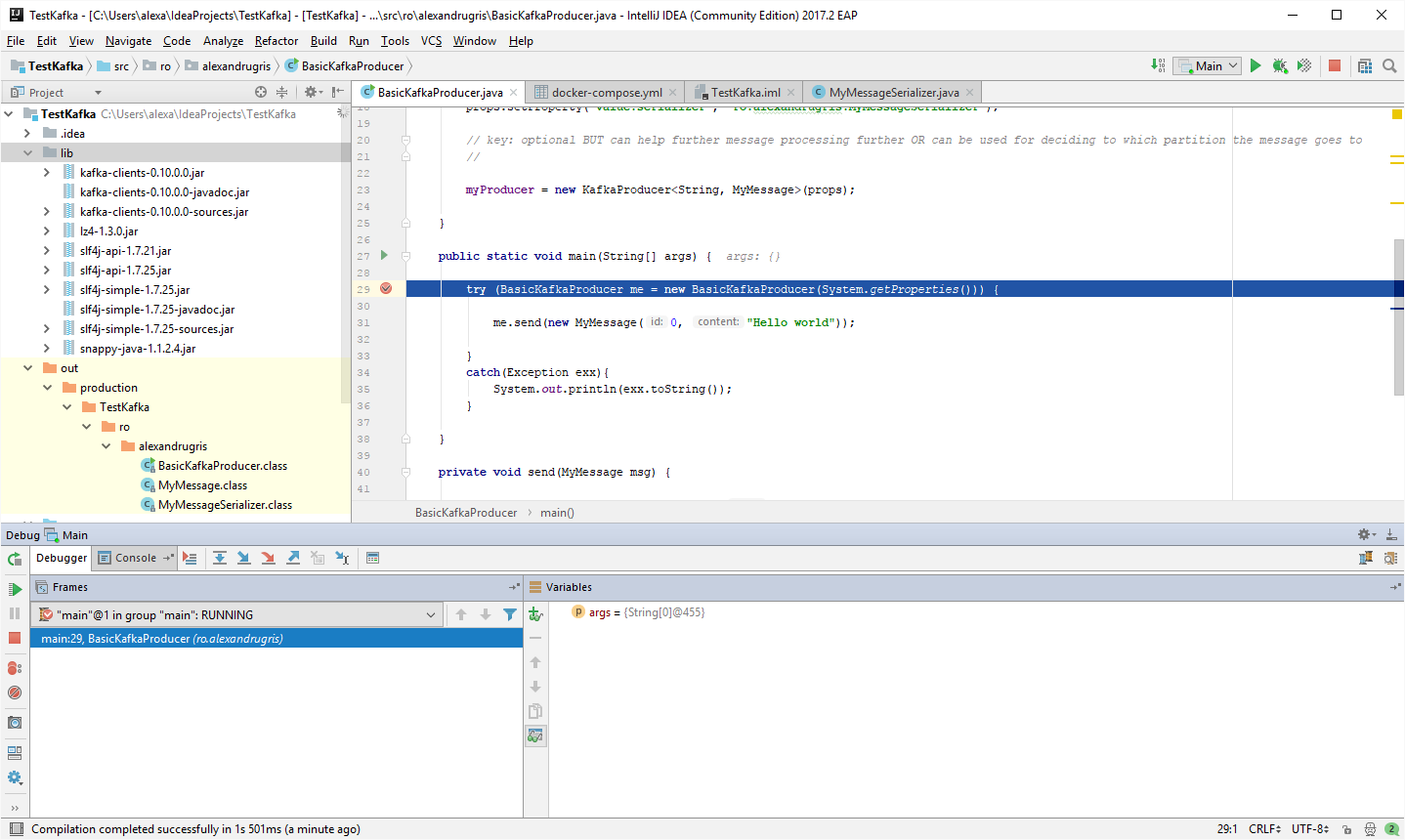
Cluster up, with bash started on app node
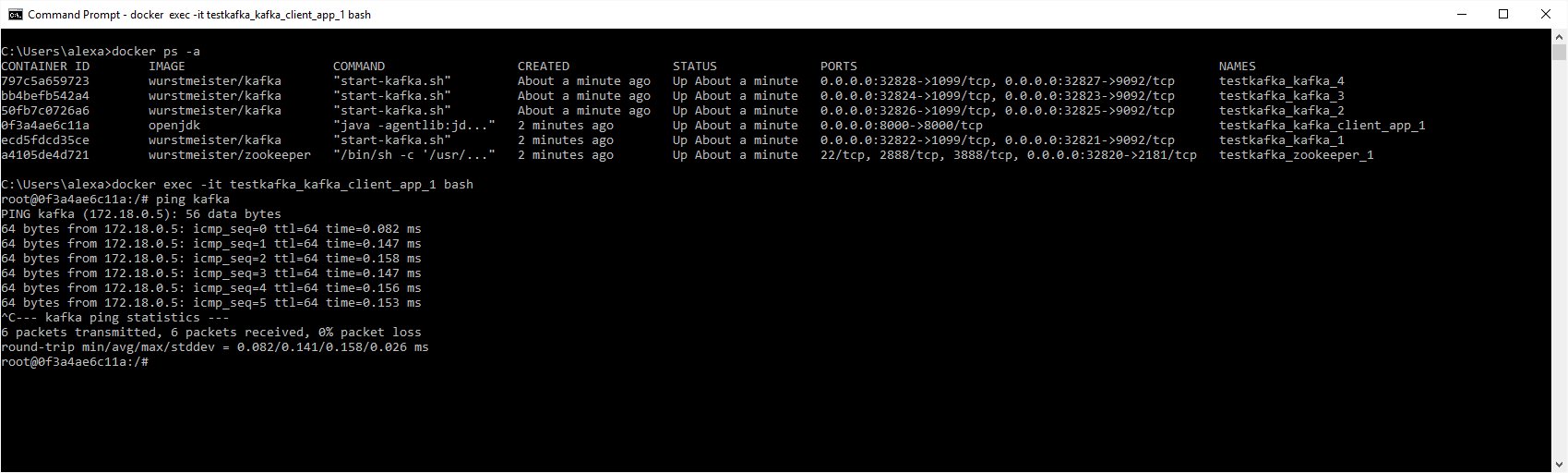
Produced messages in the queue
New topic created, ballanced, with 5 partitions and 2 replicas
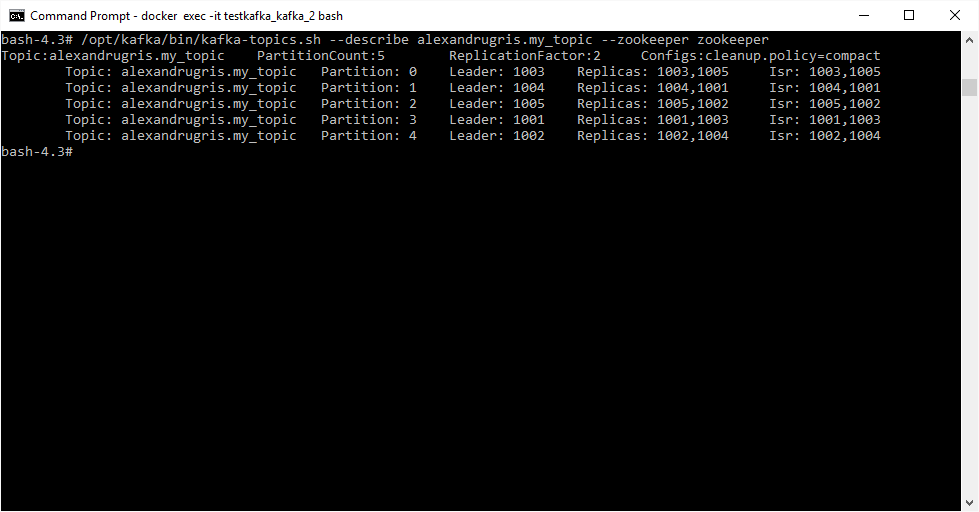
Partitioning and producing messages
Kafka has a simple yet powerful method for selecting to which partition the message is routed at the time of producing. The topic with its associated partitions is created either automatically when the producer is first run, like it is the case in our demo, or using the kafka-topics.sh tool. This behavior is configured through a setting in the config.settings file when the queue is started.
The algorithm for routing to partitions goes as follows:
- If the partition is directly specifiedand it is a valid partition, then the message is routed directly to it.
- Else, if the key has been specified, then if a custom partitioner is present, specified at the creation of the Producer instance through
partitioner.classproperty, then this custom partitioner is used. - If the key has been specified but there is no custom partitioner instantiated, then the default paritioner will hash the key and will perform a modulo operation to assign the designated partition.
The following snippet is the producer code initialized with a by-first-letter partitioner:
public BasicKafkaProducer(Properties props){
props.setProperty("partitioner.class", "ro.alexandrugris.ByDestinationPartitioner");
myProducer = new KafkaProducer<String, MyMessage>(
props,
new org.apache.kafka.common.serialization.StringSerializer(),
new ro.alexandrugris.ObjectSerializer<MyMessage>()
);
}
public static void main(String[] args) {
try (BasicKafkaProducer me = new BasicKafkaProducer(System.getProperties())) {
me.send(Arrays.asList(
new MyMessage("alexandru.gris", "Hello World"),
new MyMessage("olga.muravska", "Hello World"),
new MyMessage("olga.muravska", "Hello World"),
new MyMessage("alexandru.gris", "Hello World"),
new MyMessage("alexandru.gris", "Hello World"),
new MyMessage("gris.laurian", "Hello World"),
new MyMessage("gris.laurian", "Hello World")
));
}
catch(Exception exx){
System.out.println(exx.toString());
}
}
private void send(List<MyMessage> msgs) {
Object lock = new Object();
class Counter {
int cnt = msgs.size();
int decrement(){ return --cnt; }
}
Counter cnt = new Counter();
for(MyMessage msg : msgs) {
myProducer.send(new ProducerRecord<String, MyMessage>(TOPIC_NAME, msg.destination(), msg), (RecordMetadata metadata, Exception exception) -> {
if (exception != null) {
System.out.println(exception.toString());
} else {
System.out.println(metadata.toString());
}
synchronized (lock) {
if (cnt.decrement() == 0) lock.notify();
}
});
}
synchronized (lock) {
try { lock.wait(); } catch(Exception exx){}
}
}
The producer is thread safe and should generally be shared among all threads for best performance.
The producer manages a single background thread that does I/O as well as a TCP connection to each of the brokers it needs to communicate with. Failure to close the producer after use will leak these resources. Apache kafka is optimized for high throughput and, therefore, uses microbatching in its producer and consumer clients (RecordAccumulator low level class). For each topic-partition combination, internally a RecordBatch keeps track of these messages.
Batch options:
batch.size: size of eachRecordBatchlinger.ms: how many milliseconds a buffer waits for new messages if not fullbatch.memory: memory size for allRecordBatchesmax.block.ms: how many milliseconds the send method will be blocked for - used for creating back pressure on the producer to generate and send more messages to the buffer
On return from send, the queue sends back a RecordMetadata with the result of the successfull or unsuccesfull transmission.
Delivery guarantees properties:
acks: (0: fire and forget. 1: leader acknowledgement - only receives from the leader that the message has been stored, not from all the partitions. 2: quorum acknowledgement - all in sync replicas confirm the receipt )retries: how many times the producer will retry sending the messageretry.backoff.ms: backoff time between each retry
Message order is preserved only within a given partition. Retries and backoff destroy this quarantee. If we still want this guarantee enforced, we need to set max.in.flight.request.per.connection=1, but this dramatically affects performance.
All producer configuration options are defined as static strings in the ProducerConfig class.
The result of the per-first-letter partitioner when run:
$>/opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server kafka:9092 --topic alexandrugris.my_topic --partition 0 --from-beginning
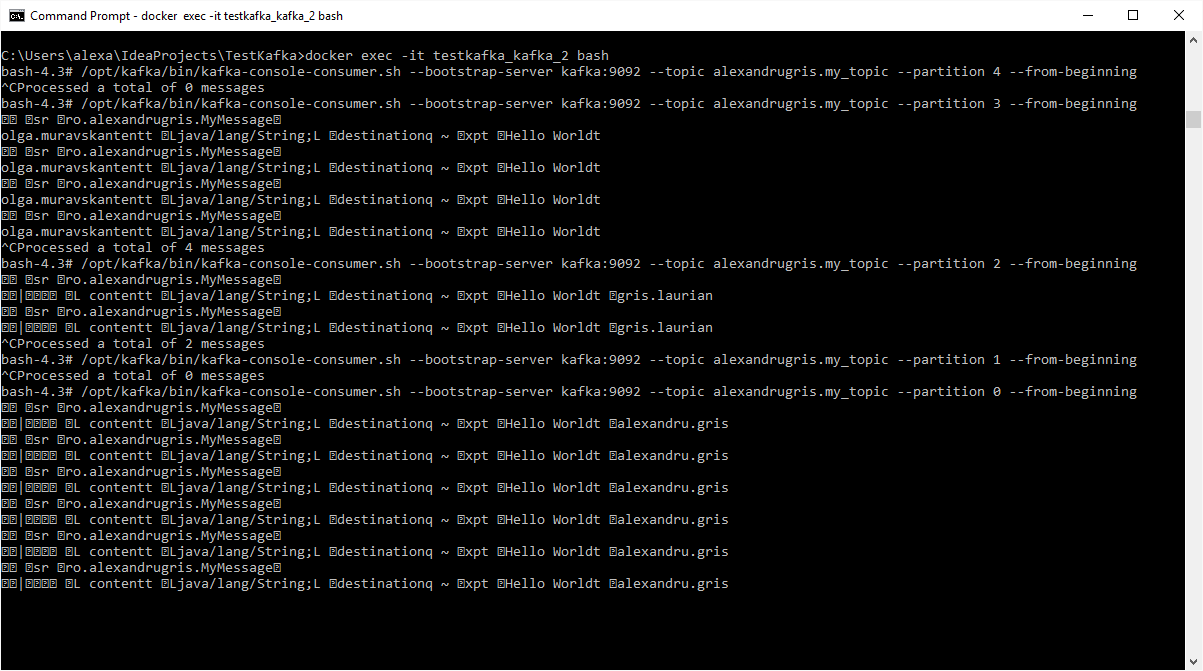
Consuming messages
Basic notions:
- There is one thread per Kafka consumer
- Polling is a single threaded operation
Properties:
enable.auto.commit=true- allow Kafka to manage when last committed offset is incrementedauto.commit.interval=5000- together withenable.auto.commitenables Kafka consumer to autocommit every XXX milliseconds.auto.offset.reset="latest" or "earliest"- from where to start reading the messages from a partition - latest / earliest refers to known committed offset.
Kafka keeps track of consumer offsets in a Kafka topic named __consumer_offsets, which is partitioned across 50 partitions.
bash-4.3# /opt/kafka/bin/kafka-topics.sh --describe --zookeeper zookeeper:2181 --topic __consumer_offsets
The KafkaConsumer API has functions to manually retreive and / or reset the position in the stream on a per topic/partition basis. This allows true manual cursor movement, very similar to working with a file. It has also options to pause / resume a subscribed topic when there are higher priority messages to consider.
Manual offset API:
- seek()
- seekToBeginning()
- seekToEnd()
- position()
Flow control API:
- pause partition
- resume partition
Rebalance listeners:
// subscribe to all partitions in a topic
consumer.subscribe(topicPatterns.stream().map(TopicPattern::getTopic).collect(Collectors.toSet()), new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
// do something here
// https://kafka.apache.org/0101/javadoc/org/apache/kafka/clients/consumer/ConsumerRebalanceListener.html
// for instance, save restore offset from an external store
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
// do something here
}
});
If we set the enable.auto.commit=false we need to use one of the two API functions commitSync() or commitAsync() to advance the last known committed offset. commitSync retries in case of failure. The retry is controlled by the
retries.backoff.ms setting. In case of unrecoverable error, a CommitFailedException is thrown. commitAsync receives a callback as parameter for the calling application to know when the commit has occured. It does not automatically retry.
How to start everytime from beginning in Kafka
Scaling out - consumer groups:
By sharing the group.id property, a group of processes can consume messages together in parallel, advancing the offset in a collaborative way, thus distributig the burden of message processing to several cores / machines.
The Group Coordinator is monitoring and taking care of work distribution and group membership. It controls availability of consumer nodes through two parameters:
- heartbeat.interval.ms=3000 - how often consumers send heartbeats to Kafka
- session.timeout.ms=30000 - how long before the consumer is considered down and removed from group membership
Partition allocation in consumer groups:
If the number of consumers == the number of partitions, the group coordinator will allocate to each consumer a partition in a 1:1 setup.
If the number of consumers > the number of partitions, there will be idle consumers until more partitions become available.
Otherswise, partitions will be allocated to consumers so that each consumer consumes full partitions.
Very important:
Partition allocation in consumer groups work as described below IF the consumer subscribes to the full topic. Otherwise, if subscribed directly to partitions, all data will be distributed to all consumers independent of the consumer group allocation. This is because all consumers read from the same last committed offset on, since the commit message (consumer.commitSync()) arrives to the queue too late, when the messages have already been read.
This means we need to change the client as follows:
// subscribe to all partitions in a topic -> uncomment the line below if part of a consumer group
consumer.subscribe(topicPatterns.stream().map(TopicPattern::getTopic).collect(Collectors.toSet()));
// subscribe to specific partitions -> comment the line below if part of a consumer group
// consumer.assign(topicPatterns.stream().map( TopicPattern::getPartition).collect(Collectors.toList()));
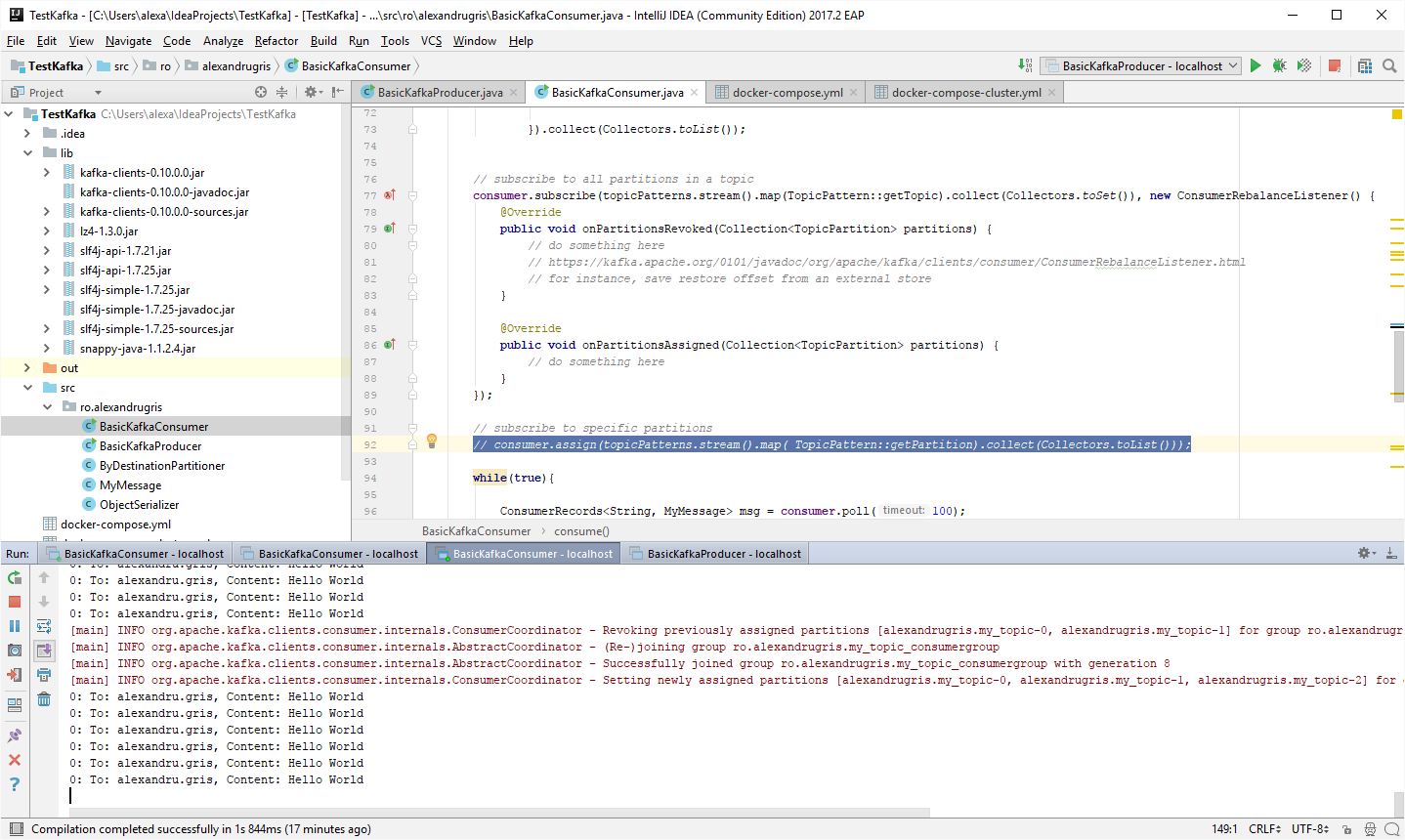
Topics not covered:
Kafka Schema Registry: - Avro schema registry and serializers
- https://www.confluent.io/blog/schema-registry-kafka-stream-processing-yes-virginia-you-really-need-one/
- Example Producer
Apache Kafka Connect: - standardized integration pipeline with Kafka in the middle. http://docs.confluent.io/current/connect/index.html
Connect makes it simple to use existing connector implementations for common data sources and sinks to move data into and out of Kafka. Kafka Connect’s applications are wide ranging.
A source connector can ingest entire databases and stream table updates to Kafka topics or even collect metrics from all of your application servers into Kafka topics, making the data available for stream processing with low latency.
A sink connector can deliver data from Kafka topics into secondary indexes like Elasticsearch or into batch systems such as Hadoop for offline analysis.
Kafka Streams: - Stream processing with kafka
Compaction: http://kafka.apache.org/documentation.html#compaction - keeping only the last updated value for a key
Best source: http://kafka.apache.org/documentation/